Java 8: Sifaka requires the 64-bit version of Java 8. If you don't have it already, download the Java 8 Runtime Environment (JRE).
Download Sifaka: It is available from SourceForge, on the Lemur Project page.
Index documents: Sifaka uses a document index that enables it to search and analyze your documents quickly. Thus, the next step is to build an index for your documents.
To build a document index: Sifaka can index plain text, the Reuters-21578 dataset from UCI, simplified TREC documents, the Wall Street 1987-1992, html documents, warc files, and tweets in the Twitter Spritzer format. (The Document Parser Tutorial provides information about each supported format and how to build parsers for other document formats.)
Run Sifaka Build Index Application: The process for starting Sifaka Build Index is a little different on different operating systems.
Windows: There are several options for running Sifaka in Windows.
All versions: Double-click on sifakaBuildIndex.jar. This is the best choice for most people.
Windows 7: Open a command prompt. Navigate to the directory which contains sifaka.jar. Type: java -jar sifakaBuildIndex.jar
Windows 10: Open a bash shell. Navigate to the directory which contains sifaka.jar. Type: java -jar sifakaBuildIndex.jar
Mac: Open a terminal. Navigate to the directory which contains sifaka.jar. Type: java -jar sifakaBuildIndex.jar
Linux: Open a terminal. Navigate to the directory which contains sifaka.jar. Type: java -jar sifakaBuildIndex.jar
-
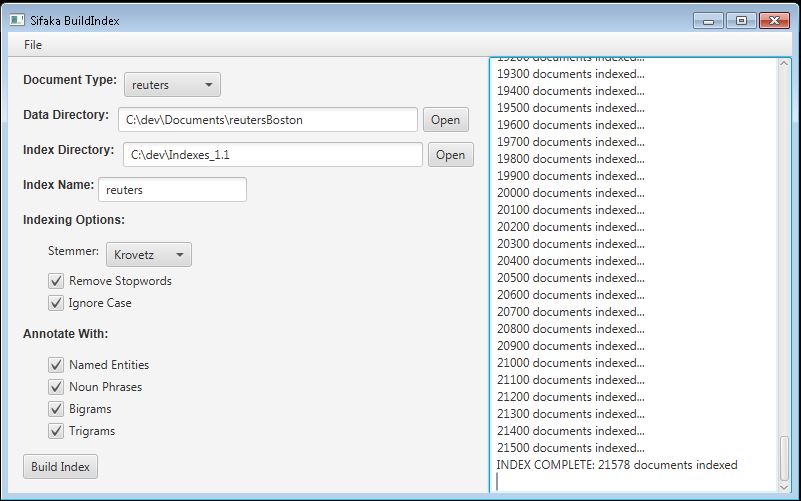
Create a Sifaka index: Use Sifaka BuildIndex to index documents in a directory with specified indexing options and annotations.
- To build an index with the Reuters-21578 Text Categorization Data Set from UCI, download the dataset: reuters21578.tar.gz. (Refer to the document parser tutorial to build an index with a different set of documents.)
- Unzip the archive.
- Specify the indexing parameters.
- Document Type: reuters
- Data Directory: The directory where reuters21578 has been unzipped.
- Index Directory: The directory to store the Sifaka index.
- Index Name: The name of the directory which is created and contains the built index.
- Indexing Options: Choose Krovetz, Porter, or no stemmer. Choose whether to remove stopwords and ignore case.
- Annotate With: Select the annotations to store in the index. These annotations can be used for text analysis such as CoOccurrence and Frequency with the Sifaka TextMiner.
- Press the Build Index button to start indexing documents.