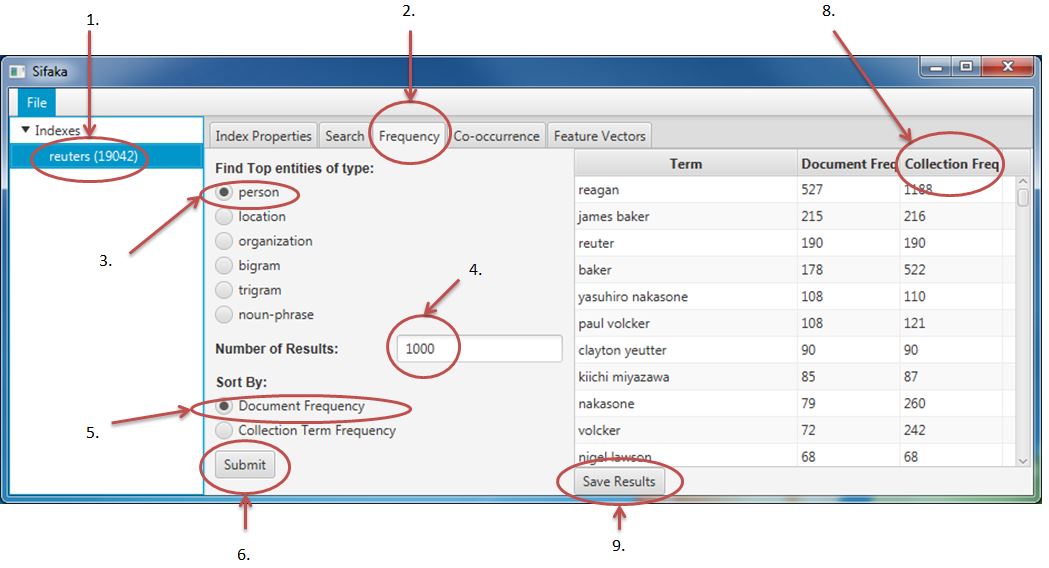
Select the index in the Left Navigation.
Select the Frequency tab in the right content tab pane.
Select the person radio button under Find Top entities of type.
Enter 1000 in the Number of Results text box.
Select the Document Frequency for Sort By.
Press Submit. This analysis will take a few minutes. A progress indicator will appear as Sifaka is calculating the top entities. Note: If this experiment takes longer than 10 minutes, check that the correct java version is installed.
The people that occur in the greatest number of documents will display in a table to the right of the input.
Click on the Collection Freq column header to sort the people by how many times they appear in the corpus rather than the number of documents in which they appear. Note: This list still contains the original result set. The result set was truncated based on the Document Frequency count which was selected upon submitting.
Click the Save Results button to save this table in CSV format.
Right click on "paul volcker" and select Search from the context menu. The search tab will open with "paul volcker" automatically populated as the search query.